一.引入
二分图匹配算法是一个非常有用的算法,我们首先从一个简单的题目引入。
给你n个水果,m个箱子,每个水果只能被放在指定的几个箱子里,每个盒子只能放一个水果,问如何安排能使的放在盒子里的水果最多。
怎么写?暴力,可以试试。但不管是暴力还是什么算法,都需要面对一个情况——后面的水果如果没盒子放了,不能不管不顾,应该腾空间。对,腾。
二分图算法的最重要思想就是腾
二.算法流程
二分图有两种主流算法,一个是匈牙利算法,一个是KM算法。
我们先讲解匈牙利算法(KM算法见目录第5项) 为了方便理解,我们先画个图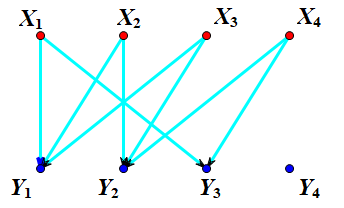 \(X_{1}\)~\(X_{4}\)指的是水果,\(Y_{1}\)~\(Y_{4}\)指的是盒子,每个水果有它自己的喜好。 这时,匈牙利算法带着你找到了\(X_{1}\)水果,你发现\(Y_{1}\)是个空盒子,于是你把\(X_{1}\)放入\(Y_{1}\)中(连一条红线)
\(X_{1}\)~\(X_{4}\)指的是水果,\(Y_{1}\)~\(Y_{4}\)指的是盒子,每个水果有它自己的喜好。 这时,匈牙利算法带着你找到了\(X_{1}\)水果,你发现\(Y_{1}\)是个空盒子,于是你把\(X_{1}\)放入\(Y_{1}\)中(连一条红线)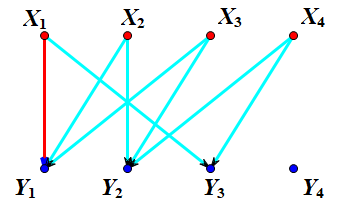 接着,匈牙利算法带着你找到了\(X_{2}\),你发现\(Y_{2}\)是个空盒子,于是你把\(X_{2}\)放入了\(Y_{2}\)中(连一条红线)
接着,匈牙利算法带着你找到了\(X_{2}\),你发现\(Y_{2}\)是个空盒子,于是你把\(X_{2}\)放入了\(Y_{2}\)中(连一条红线) 你接着往后面找,发现了\(X_{3}\),但是你发现\(Y_{1}\)、\(Y_{2}\)都已经放了东西了,怎么帮,就这么放手不管吗? 不,匈牙利算法告诉你,你需要做一些尝试。于是你试着把\(X_{3}\)放入\(Y_{2}\),并且准备给\(X_{2}\)重新找个盒子,但是你发现\(Y_{1}\)同样有水果了……于是你故技重施,这样你就要给\(X_{1}\)重新找个盒子了,正巧,\(Y_{3}\)是空着的,于是你便将\(X_{1}\)放入了\(Y_{3}\) 那么我们在不断寻找的过程中,经历了\(X_{?}\)-->\(Y_{?}\)--->\(X_{?}\)--->……的路径,我们称其为增广路 (下图中,黄边是临时拆卸的边,表示正在尝试)
你接着往后面找,发现了\(X_{3}\),但是你发现\(Y_{1}\)、\(Y_{2}\)都已经放了东西了,怎么帮,就这么放手不管吗? 不,匈牙利算法告诉你,你需要做一些尝试。于是你试着把\(X_{3}\)放入\(Y_{2}\),并且准备给\(X_{2}\)重新找个盒子,但是你发现\(Y_{1}\)同样有水果了……于是你故技重施,这样你就要给\(X_{1}\)重新找个盒子了,正巧,\(Y_{3}\)是空着的,于是你便将\(X_{1}\)放入了\(Y_{3}\) 那么我们在不断寻找的过程中,经历了\(X_{?}\)-->\(Y_{?}\)--->\(X_{?}\)--->……的路径,我们称其为增广路 (下图中,黄边是临时拆卸的边,表示正在尝试)
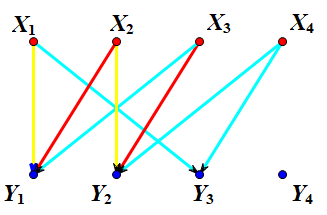
 于是皆大欢喜,大家都有了自己的归宿。 接着找到了\(X_{4}\),但是不管怎么腾都没办法了,只能把\(X_{4}\)放外面吹西北风了
于是皆大欢喜,大家都有了自己的归宿。 接着找到了\(X_{4}\),但是不管怎么腾都没办法了,只能把\(X_{4}\)放外面吹西北风了 所以二分图算法最重要的一点就是腾,能腾就要大力腾
三.代码(匈牙利算法)
Zju1140 Courses 课程
Description 给出课程的总数P(1<=p<100),学生的总数N(1<=N<=300) 每个学生可能选了一门课程,也有可能多门,也有可能没有. 要求选出P个学生来组成一个协会,每个学生代表一门课程, 且每门课程都有一个学生来代表它。Input
先是测试数据的个数。 再是P,N 下列P行,代表从第一门课到第P门课程的学生选修的情况。先给出有多少人选修, 再是这些人的学号.Output
可否组成一个这样的协会Sample Input
2 3 3 3 1 2 3 2 1 2 1 1 3 3 2 1 3 2 1 3 1 1Sample Output
YES NO裸的二分图最大匹配,直接上代码
/*program from Wolfycz*/#include#include #include #include #include #define inf 0x7f7f7f7fusing namespace std;typedef long long ll;typedef unsigned int ui;typedef unsigned long long ull;inline int read(){ int x=0,f=1;char ch=getchar(); for (;ch<'0'||ch>'9';ch=getchar()) if (ch=='-') f=-1; for (;ch>='0'&&ch<='9';ch=getchar()) x=(x<<1)+(x<<3)+ch-'0'; return x*f;}inline void print(int x){ if (x>=10) print(x/10); putchar(x%10+'0');}const int N=1e2,M=3e2;int path[M+10],pre[N*M+10],now[N+M+10],child[N*M+10];int tot,n,m;bool use[M+10];void join(int x,int y){pre[++tot]=now[x],now[x]=tot,child[tot]=y;}bool check(int x){//大力腾空间 for (int p=now[x],son=child[p];p;p=pre[p],son=child[p]){ if (use[son]) continue; //如果它被腾过,就不能再腾了 use[son]=1; if (path[son]<0||check(path[son])){path[son]=x;return 1;} //如果说一点是空的,或者说它能被腾出空间,我们就更新一下 } return 0;}void work(){ int res=0; for (int i=1;i<=n;i++){ memset(use,0,sizeof(use)); //每次初始化,腾的时候用到 if (check(i)) res++; } printf(res==n?"YES\n":"NO\n");}void init(){ tot=0; memset(now,0,sizeof(now)); memset(path,255,sizeof(path));}int main(){ for (int Data=read();Data;Data--){ init(); n=read(),m=read(); for (int i=1;i<=n;i++) for (int x=read(),j;x;x--) j=read(),join(i,j); work(); } return 0;}
四.关于二分图的一些证明
(环的最大匹配方式有多种这里不予讨论)
设最大匹配数为\(K\) ,点数为\(N\)
最小点覆盖集:就是用最少的点集\(G\),使这个图上的所有线段的左端点或右端点属于\(G\)
证明: 由于所有最大匹配的线段都不相交,只要取左端点或右端点就可以,所以最大匹配的每一个线段都对应了一个点,一共有\(K\)个 因为是最大匹配,不存在增广路,当某两条线段的要取的端点相交时,可以知道那一定不是最大匹配。最大点独立集:在一个图\(M\)中,取最多的点,使得每个点都互不相邻
证明: 当一条线段\(AB\)属于最大匹配中的边时,它一定有一个端点没有连其他的边,所以最大匹配的线段上一共有\(K\)个, 而不属于最大匹配的线段上的有\(N-2*K\)个(每条最大匹配的线段都对应了两个点) 因为我们取的是没有连其他边的端点,自然也就不存在不在最大匹配的线段上的点与其相邻 所以一共有\(N-2*K+K=N-K\)个点最小边覆盖:取最少的边集\(G\),使得所有的顶点都在\(G\)中
证明: 其实与最大点独立集差不多,只是点也可以视为边,最大匹配中的边覆盖了\(2*k\)点, 剩下的\(N-2*K\)个点又要用\(N-2*K\)条线段去覆盖,所以一共是\(N-2*K+K=N-K\)最小路径覆盖:在一个有向图中,用不相交的路径覆盖整个图
证明: 因为每个点最初都是一条路径,总共有N条不相交路径。我们每次在二分图里加一条边就相当于把两条路径合成了一条路径,因为路径之间不能有公共点,所以加的边之间也不能有公共点,而最多能合并\(K\)次,所以答案是\(N-K\)五.KM算法
匈牙利算法虽好,也有一定的局限性,如果题目要求的不是最大匹配而是最大权值匹配的话,匈牙利算法就显得无能为力了,这样我们就需要用到一种新算法,KM算法
一般对KM算法的描述,基本上可以概括成以下几个步骤:
(1) 初始化可行标杆 (2) 用匈牙利算法寻找完备匹配 (3) 若未找到完备匹配则修改可行标杆 (4) 重复(2)(3)直到找到相等子图的完备匹配完备匹配:如果一个匹配中,图中的每个顶点都和图中某条边相关联,则称此匹配为完全匹配,也称作完备匹配。
定理:设\(M\)是一个带权完全二分图\(G\)的一个完备匹配,给每个顶点一个可行顶标(第\(i\)个\(x\)顶点的可行标用\(lx[i]\)表示,第\(j\)个\(y\)顶点的可行标用\(ly[j]\)表示),如果对所有的边(i,j) in G,都有\(lx[i]+ly[j]>=w[i][j]\)成立(\(w[i][j]\)表示边的权),且对所有的边(i,j) in M,都有\(lx[i]+ly[j]=w[i][j]\)成立,则M是图G的一个最优匹配。
那么可行标杆是什么?为了方便理解,我们通过一个实例,和一些比方来解释
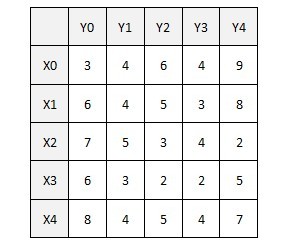 我们假定\(X_{?}\)为一些客人,\(Y_{?}\)为一些商品,客人们对商品有一定的期望值,你需要让客人买一些商品,使得他们的期望值最大(不考虑经济问题)
我们假定\(X_{?}\)为一些客人,\(Y_{?}\)为一些商品,客人们对商品有一定的期望值,你需要让客人买一些商品,使得他们的期望值最大(不考虑经济问题) 那么这些客人在进行商品分配的时候难免会有一些争端,于是我们可以找到一条增广路,增广路上一定有奇数个节点,并且必定是客人点多出来一个。因此,我们需要对客人和商品的标杆进行些许的调整,是的二分图中能加进来一些新的点满足客户的需求,解决他们的纠纷。
我们设\(lx\)为客人的标杆,\(ly\)为商品的标杆。 客人的标杆必然是他们的期望值,那么商品的标杆呢,肯定就是它们的期望增高值 因此,\(lx\)的初值就是某客户对所有商品的最大期望值,\(ly\)的初值为零。 当当前标杆找不到完备匹配时,我们就要让多出来客户能买其他未被选中的商品,所以令\(d=min\){ \(lx[i]+ly[j]-w[i][j]\)}(\(i\)为增广路上客户点,\(j\)为不在增广路上的商品点)i,j的位置很好理解,肯定是有争执的客人找没有争执的商品 那么\(d\)就是我要降低的值,于是我给增广路上所有的客人的最大期望值全部降低\(d\),但是我们不能减多了,每次整体只能减\(d\),所以我们要将增广路上的所有商品期望都加上\(d\),这样就能保证整体的稳定,并且能够加进来新的商品,以满足客户的需求。 (讲的不好,读者们还是边看看代码吧)六.代码(KM算法)
Description
You were just hired as CEO of the local junkyard.One of your jobs is dealing with the incoming trash and sorting it for recycling.The trash comes every day in n containers and each of these containers contains certain amount of each of the n types of trash.Given the amount of trash in the containers find the optimal way to sort the trash.Sorting the trash means putting every type of trash in separate container.Each of the given containers has infinite capacity.The effort for moving one unit of trash from container i to j is 1 if i != j otherwise it is 0.You are to minimize the total effort. 你受聘于当地的垃圾处理公司任CEO,你的一项工作是处理引进的垃圾,以及分类垃圾以进行循环利用。每天,垃圾会有几个集装箱运来,每一个集装箱都包含几种垃圾。给定集装箱里垃圾的数目,请找出最佳的途径去分类这些垃圾。分类垃圾即把每种垃圾分开装到不同的集装箱中。每个集装箱的容量都是无限的。搬动一个单位的垃圾需要耗费代价,从集装箱i到j是1(i<>j,否则代价为0),你必须把代价减到最小。Input
The first line contains the number n (1 <= n <= 150), the rest of the input file contains the descriptions of the containers.The 1 + i-th line contains the desctiption of the i-th container the j-th amount (0 <= amount <= 100) on this line denotes the amount of the j-th type of trash in the i-th container. 第一行为n (1 <= n <= 150),以下为集装箱的情况。第i+1行为第i个集装箱中的j种垃圾的数量amount(0 <= amount <= 100)。Output
You should write the minimal effort that is required for sorting the trash. 分类这些垃圾的所需的最小代价。Sample Input
4 62 41 86 94 73 58 11 12 69 93 89 88 81 40 69 13Sample Output
650/*program from Wolfycz*/#include#include #include #include #include #define inf 0x7f7f7f7fusing namespace std;typedef long long ll;typedef unsigned int ui;typedef unsigned long long ull;inline int read(){ int x=0,f=1;char ch=getchar(); for (;ch<'0'||ch>'9';ch=getchar()) if (ch=='-') f=-1; for (;ch>='0'&&ch<='9';ch=getchar()) x=(x<<1)+(x<<3)+ch-'0'; return x*f;}inline void print(int x){ if (x>=10) print(x/10); putchar(x%10+'0');}const int N=1.5e2;int path[N+10],lx[N+10],ly[N+10];int map[N+10][N+10];bool visx[N+10],visy[N+10];int n,ans;bool check(int x){ visx[x]=1; for (int y=1;y<=n;y++){ if (!visy[y]&&lx[x]+ly[y]==map[x][y]){ visy[y]=1; if (path[y]<0||check(path[y])){ path[y]=x; return 1; } } } return 0;}int Km(){ int sum=0; memset(path,-1,sizeof(path)); for (int i=1;i<=n;i++){ while (1){ memset(visx,0,sizeof(visx)); memset(visy,0,sizeof(visy)); if (check(i)) break; int d=inf; for (int i=1;i<=n;i++) if (visx[i]) for (int j=1;j<=n;j++) if (!visy[j]) d=min(d,lx[i]+ly[j]-map[i][j]); for (int i=1;i<=n;i++) if (visx[i]) lx[i]-=d; for (int i=1;i<=n;i++) if (visy[i]) ly[i]+=d; } } for (int i=1;i<=n;i++) if (path[i]!=-1) sum+=map[path[i]][i]; return sum;}int main(){ n=read(); for (int i=1;i<=n;i++){ lx[i]=-inf; for (int j=1;j<=n;j++) ans+=map[i][j]=read(),lx[i]=max(lx[i],map[i][j]); } printf("%d\n",ans-Km()); return 0;}